安装elasticsearch6.5.1
docker run -p 9200:9200 -p 9300:9300 -e "http.host=0.0.0.0" -e "http.cors.enabled=true" -e "http.cors.allow-origin="*"" -d docker.elastic.co/elasticsearch/elasticsearch:6.5.1源码地址:https://github.com/KennFalcon/elasticsearch-analysis-hanlp
安装
进入容器
docker exex -it <容器名> /bin/bash
安装jdk1.8
yum install java-1.8.0-openjdk* -y
java -version
安装elasticsearch-analysis-hanlp
./bin/elasticsearch-plugin install https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v6.5.1/elasticsearch-analysis-hanlp-6.5.1.zip
下载hanlp数据包
查看hanlp数据的地址:https://github.com/hankcs/HanLP/releases 下载data-for-1.7.0.zip
删除原有的基础data
cd /usr/share/elasticsearch/plugins/analysis-hanlp
rm -rf data
wget http://hanlp.linrunsoft.com/release/data-for-1.7.0.zip
unzip data-for-1.7.0.zip
chmod -R 777 data/
rm -rf data-for-1.7.0.zip
修改中文文件名 hanlp.properties中已经修改过了 对应配置文件中的CustomDictionaryPath
cd /usr/share/elasticsearch/plugins/analysis-hanlp/data/dictionary/custom
mv \#U4eba#U540d#U8bcd#U5178.txt ModernChineseSupplementaryWord.txt
mv \#U5168#U56fd#U5730#U540d#U5927#U5168.txt ChinesePlaceName.txt
mv \#U673a#U6784#U540d#U8bcd#U5178.txt PersonalName.txt
mv \#U73b0#U4ee3#U6c49#U8bed#U8865#U5145#U8bcd#U5e93.txt OrganizationName.txt
mv \#U4e0a#U6d77#U5730#U540d.txt ShanghaiPlaceName.txt
修改hanlp root路径为绝对路径
vi /usr/share/elasticsearch/config/analysis-hanlp/hanlp.properties
root=/usr/share/elasticsearch/plugins/analysis-hanlp/
重启容器
docker restart <容器名>添加自定义词典热更新
cd /usr/share/elasticsearch/plugins/analysis-hanlp/data/dictionary/custom
vi Test.txt
西双版纳的姑娘
我爱蓝天
我爱
vi /usr/share/elasticsearch/config/analysis-hanlp/hanlp.properties
在ShanghaiPlaceName.txt后面添加; Test.txt
# Custom dictinary path
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; ModernChineseSupplementaryWord.txt; ChinesePlaceName.txt ns; PersonalName.txt; OrganizationName.txt; ShanghaiPlaceName.txt; Test.txt ns;data/dictionary/person/nrf.txt nrf;
等待1分钟后,词典自动加载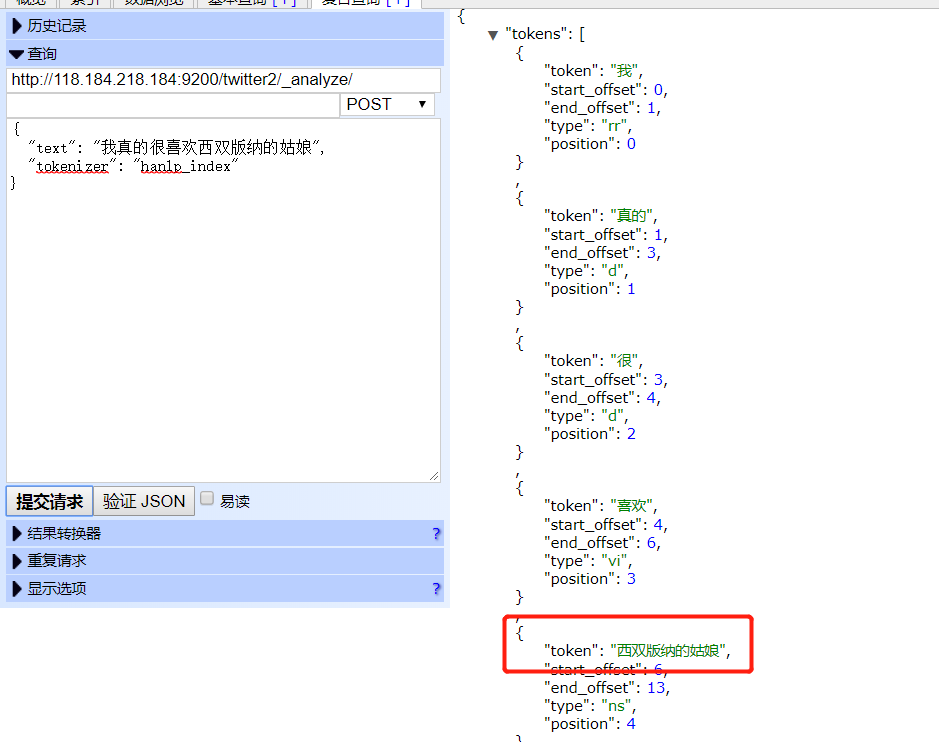
测试
POST http://localhost:9200/twitter2/_analyze
{
"text": "美国阿拉斯加州发生8.0级地震",
"tokenizer": "hanlp_index"
}{
"tokens" : [
{
"token" : "美国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "nsf",
"position" : 0
},
{
"token" : "阿拉斯加州",
"start_offset" : 0,
"end_offset" : 5,
"type" : "nsf",
"position" : 1
},
{
"token" : "发生",
"start_offset" : 0,
"end_offset" : 2,
"type" : "v",
"position" : 2
},
{
"token" : "8.0",
"start_offset" : 0,
"end_offset" : 3,
"type" : "m",
"position" : 3
},
{
"token" : "级",
"start_offset" : 0,
"end_offset" : 1,
"type" : "q",
"position" : 4
},
{
"token" : "地震",
"start_offset" : 0,
"end_offset" : 2,
"type" : "n",
"position" : 5
}
]
}提供的分词方式说明
hanlp: hanlp默认分词
hanlp_standard: 标准分词
hanlp_index: 索引分词
hanlp_nlp: NLP分词
hanlp_n_short: N-最短路分词
hanlp_dijkstra: 最短路分词
hanlp_crf: CRF分词(在hanlp 1.6.6已开始废弃)
hanlp_speed: 极速词典分词



