介绍
主要实现单库单表千万数据的压力 所以实现了单库分表 然后再加读写分离实现的解决方案呀
读写分离
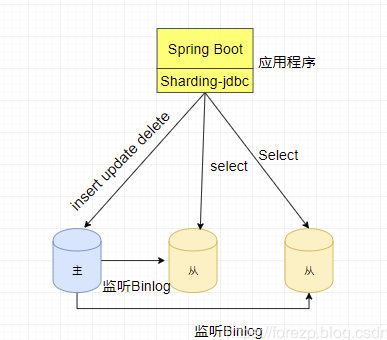
在上一篇文章介绍了如何使用Sharing-JDBC实现数据库的读写分离。读写分离的好处就是在并发量比较大的情况下,将查询数据库的压力
分担到多个从库中,能够满足高并发的要求。比如上一篇实现的那样,架构图如下:
数据分表
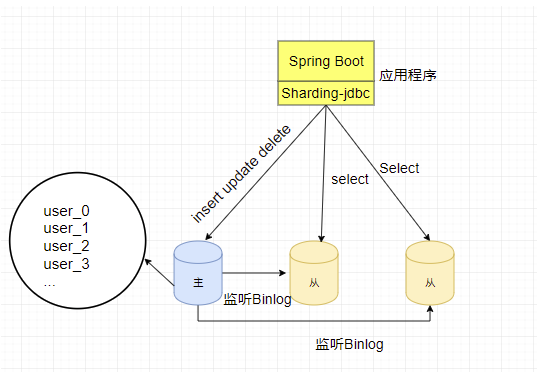
当数据量比较大的时候,比如单个表的数据量超过了500W的数据,这时可以考虑将数据存储在不同的表中。比如将user表拆分为四个表user_0、user_1、
user_2、user_3装在四个表中。此时如图所示:
在主库初始化Mysql数据的脚本,初始化完后,从库也会创建这些表,脚本信息如下:
CREATE DATABASE /*!32312 IF NOT EXISTS*/`cool2` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `cool2`;
/*Table structure for table `user_0` */
DROP TABLE IF EXISTS `user_0`;
CREATE TABLE `user_0` (
`id` bigint(64) NOT NULL AUTO_INCREMENT,
`username` varchar(12) NOT NULL,
`password` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=149 DEFAULT CHARSET=utf8;
/*Table structure for table `user_1` */
DROP TABLE IF EXISTS `user_1`;
CREATE TABLE `user_1` (
`id` bigint(64) NOT NULL AUTO_INCREMENT,
`username` varchar(12) NOT NULL,
`password` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=150 DEFAULT CHARSET=utf8;
/*Table structure for table `user_2` */
DROP TABLE IF EXISTS `user_2`;
CREATE TABLE `user_2` (
`id` bigint(64) NOT NULL AUTO_INCREMENT,
`username` varchar(12) NOT NULL,
`password` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=147 DEFAULT CHARSET=utf8;
/*Table structure for table `user_3` */
DROP TABLE IF EXISTS `user_3`;
CREATE TABLE `user_3` (
`id` bigint(64) NOT NULL AUTO_INCREMENT,
`username` varchar(12) NOT NULL,
`password` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=148 DEFAULT CHARSET=utf8;本案例还是在上一篇文章的案例基础之上进行改造,工程的目录和pom的依赖见上一篇文章或者源码。在工程的配置
文件application.yml做Sharding-JDBC的配置,代码如下:
master-host: 127.0.0.1
slave1-host: 127.0.0.1
slave2-host: 127.0.0.1
sharding:
jdbc:
dataSource:
names: db-test0,db-test1,db-test2
db-test0: #org.apache.tomcat.jdbc.pool.DataSource
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://${master-host}:3340/cool2?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password:
maxPoolSize: 20
db-test1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://${slave1-host}:3341/cool2?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
username: root
password:
maxPoolSize: 20
db-test2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://${slave2-host}:3342/cool2?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
username: root
password:
maxPoolSize: 20
props:
sql:
show: true
sharding.jdbc.config.sharding.tables.user.actual-data-nodes: ds_0.user_$->{0..3}
sharding.jdbc.config.sharding.tables.user.table-strategy.standard.sharding-column: id
sharding.jdbc.config.sharding.tables.user.table-strategy.standard.precise-algorithm-class-name: com.forezp.sharedingjdbcmasterslavetables.MyPreciseShardingAlgorithm
#sharding.jdbc.config.sharding.tables.user.table-strategy.inline.sharding-column=id
#sharding.jdbc.config.sharding.tables.user.table-strategy.inline.algorithm-expression=user_${id.longValue() % 4}
sharding.jdbc.config.sharding.master-slave-rules.ds_0.master-data-source-name: db-test0
sharding.jdbc.config.sharding.master-slave-rules.ds_0.slave-data-source-names: db-test1,db-test2
server:
port: 8085在上面的配置中,sharding.jdbc.dataSource部分是配置的数据源的信息,本案例有三个数据源db-test0、db-test1、db-test2。
sharding.jdbc.config.sharding.master-slave-rules.ds_0.master-data-source-name配置的是主库的数据库名,本案例为db-test0,其中ds_0为分区名。
sharding.jdbc.config.sharding.master-slave-rules.ds_0.slave-data-source-names配置的是从库的数据库名,本案例为db-test1、db-test2。
sharding.jdbc.config.sharding.tables.user.actual-data-nodes配置的分表信息,真实的数据库信息。ds_0.user_$->{0…3},表示读取ds_0数据源的user_0、user_1、user_2、user_3。
sharding.jdbc.config.sharding.tables.user.table-strategy.standard.sharding-column配置的数据分表的字段,是根据id来分的。
sharding.jdbc.config.sharding.tables.user.table-strategy.standard.precise-algorithm-class-name是配置数据分表的策略的类,这里是自定义的类MyPreciseShardingAlgorithm。
自定义的类可以根据存放在redis的规则去匹配 MyPreciseShardingAlgorithm是根据id取模4来获取表名的,代码如下:
public class MyPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Integer> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> shardingValue) {
for (String tableName : availableTargetNames) {
if (tableName.endsWith(shardingValue.getValue() % 4 + "")) {
return tableName;
}
}
throw new IllegalArgumentException();
}
}###测试
写一个API来测试,代码如下:
@RestController
public class UserController {
Logger logger= LoggerFactory.getLogger(UserController.class);
@Autowired
private UserService userService;
@GetMapping("/users")
public Object list() {
return userService.list();
}
@GetMapping("/add")
public Object add() {
for(int i=100;i<150;i++) {
User user = new User();
user.setId(i);
user.setUsername("forezp"+(i));
user.setPassword("1233edwd");
long resutl= userService.addUser(user);
logger.info("insert:"+user.toString()+" result:"+resutl);
}
return "ok";
}
}启动Spring Boot工程,在浏览器上执行localhost:8080/add,然后去数据库中查询,可以看到user_0、user_1、user_2、user_3分别插入了数据。
然后访问localhost:8080/users,可以查询数据库中四个表中的所有数据。可见Sharding-JDBC在插入数据的时候,根据数据分表策略,将数据存储在
不同的表中,查询的时候将数据库从多个表中查询并聚合。
开启3个库的日志查询(不建议生产使用呀):
查看日志目录,并开启sql语句的日志:
mysql> show variables like '%general_log%';
mysql> set global general_log=on;开启后,重启Mysql ,上述开启日志配置将失效。
在数据库的主机的日志里面,可以看到查询的日志也验证了这个结论,如下:
2019-07-15T14:24:00.788254Z 20 Query select @@session.transaction_read_only
2019-07-15T14:24:00.796210Z 20 Query INSERT INTO user_0 (
id, username, password
)
VALUES (
100,
'forezp100',
'1233edwd'
)从库查询日志:
从主1去查询了
2019-07-15T14:18:32.890665Z 18 Query SELECT u.* FROM user_0 u order by u.id
2019-07-15T14:18:32.896601Z 18 Query SELECT u.* FROM user_2 u order by u.id
从库2去查询了
2019-07-15T14:18:32.890665Z 18 Query SELECT u.* FROM user_1 u order by u.id
2019-07-15T14:18:32.896601Z 18 Query SELECT u.* FROM user_3 u order by u.iddemo:https://github.com/ciweigg2/sharding-jdbc-example/tree/master/shareding-jdbc-master-slave-tables



