介绍
使用mysql_random_data_load将随机数据插入表中百万数据分分钟插入
源码地址:https://github.com/Percona-Lab/mysql_random_data_load/releases
备份地址:https://github.com/ciweigg2/mysql_random_data_load/releases
安装
下载安装包
https://github.com/ciweigg2/mysql_random_data_load/releases/download/v0.1.10/mysql_random_data_load_linux_amd64.tar.gz
tar xzf mysql_random_data_loader_linux_amd64.tar.gz
mv mysql_random_data_loader /usr/bin
chmod +x mysql_random_data_loader测试
创建数据库
CREATE TABLE `test`.`t3` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`tcol01` tinyint(4) DEFAULT NULL,
`tcol02` smallint(6) DEFAULT NULL,
`tcol03` mediumint(9) DEFAULT NULL,
`tcol04` int(11) DEFAULT NULL,
`tcol05` bigint(20) DEFAULT NULL,
`tcol06` float DEFAULT NULL,
`tcol07` double(10,2) DEFAULT NULL,
`tcol08` decimal(10,2) DEFAULT NULL,
`tcol09` date DEFAULT NULL,
`tcol10` datetime DEFAULT NULL,
`tcol11` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`tcol12` time DEFAULT NULL,
`tcol13` year(4) DEFAULT NULL,
`tcol14` varchar(100) DEFAULT NULL,
`tcol15` char(2) DEFAULT NULL,
`tcol16` blob,
`tcol17` text,
`tcol18` mediumtext,
`tcol19` mediumblob,
`tcol20` longblob,
`tcol21` longtext,
`tcol22` mediumtext,
`tcol23` varchar(3) DEFAULT NULL,
`tcol24` varbinary(10) DEFAULT NULL,
`tcol25` enum('a','b','c') DEFAULT NULL,
`tcol26` set('red','green','blue') DEFAULT NULL,
`tcol27` float(5,3) DEFAULT NULL,
`tcol28` double(4,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;运行
mysql_random_data_load test t3 2000 --host=ip --port=3306 --user=root --password=123456
INFO[2019-07-24T22:11:03+08:00] Starting
0s [====================================================================] 100%
INFO[2019-07-24T22:11:04+08:00] 200 rows inserted 如果这样的错 排查了很久 才发现是字段没有设置默长度呀
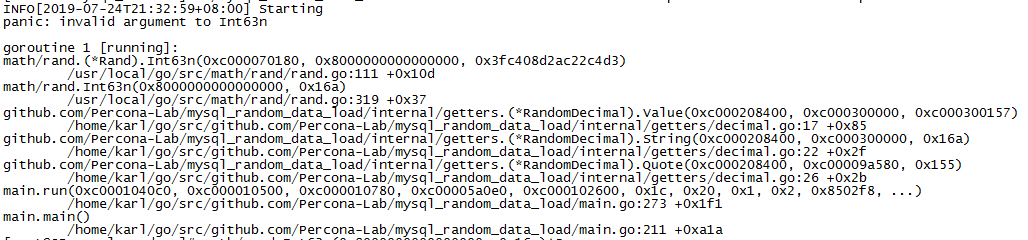
因为源码地址的创建脚本double没有默认长度 所以报错了
支持的字段
| Field type | Generated values |
|---|---|
| tinyint | 0 ~ 0xFF |
| smallint | 0 ~ 0XFFFF |
| mediumint | 0 ~ 0xFFFFFF |
| int - integer | 0 ~ 0xFFFFFFFF |
| bigint | 0 ~ 0xFFFFFFFFFFFFFFFF |
| float | 0 ~ 1e8 |
| decimal(m,n) | 0 ~ 10^(m-n) |
| double | 0 ~ 1000 |
| char(n) | up to n random chars |
| varchar(n) | up to n random chars |
| date | NOW() - 1 year ~ NOW() |
| datetime | NOW() - 1 year ~ NOW() |
| timestamp | NOW() - 1 year ~ NOW() |
| time | 00:00:00 ~ 23:59:59 |
| year | Current year - 1 ~ current year |
| tinyblob | up to 100 chars random paragraph |
| tinytext | up to 100 chars random paragraph |
| blob | up to 100 chars random paragraph |
| text | up to 100 chars random paragraph |
| mediumblob | up to 100 chars random paragraph |
| mediumtext | up to 100 chars random paragraph |
| longblob | up to 100 chars random paragraph |
| longtext | up to 100 chars random paragraph |
| varbinary | up to 100 chars random paragraph |
| enum | A random item from the valid items list |
| set | A random item from the valid items list |
支持的参数
| Option | Description |
|---|---|
| –bulk-size | Number of rows per INSERT statement (Default: 1000) |
| –debug | Show some debug information |
| –fk-samples-factor | Percentage used to get random samples for foreign keys fields. Default 0.3 |
| –host | Host name/ip |
| –max-fk-samples | Maximum number of samples for fields having foreign keys constarints. Default: 100 |
| –max-retries | Maximum number of rows to retry in case of errors. See duplicated keys. Deafult: 100 |
| –no-progressbar | Skip showing the progress bar. Default: false |
| –password | Password |
| –port | Port number |
| Print queries to the standard output instead of inserting them into the db | |
| –user | Username |
| –version | Show version and exit |
外键约束
默认支持外键关联插入
If a field has Foreign Keys constraints, random-data-load will get up to --max-fk-samples random samples from the referenced tables in order to insert valid values for the field.
The number of samples to get follows this rules:
1. Get the aproximate number of rows in the referenced table using the rows field in:
EXPLAIN SELECT COUNT(*) FROM <referenced schema>.<referenced table>1.1 If the number of rows is less than max-fk-samples, all rows are retrieved from the referenced table using this query:
SELECT <referenced field> FROM <referenced schema>.<referenced table>1.2 If the number of rows is greater than max-fk-samples, samples are retrieved from the referenced table using this query:
SELECT <referenced field> FROM <referenced schema>.<referenced table> WHERE RAND() <= <fk-samples-factor> LIMIT <max-fk-samples>


