hanlp介绍
HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点
SpringBoot集成中好像没什么效果
分词查询介绍
分词查询会将你查询的词语拆分成多个单词,然后去匹配elasticsearch里面同样将单词拆分后的数据
例子:
首先查看单词拆分的结果:
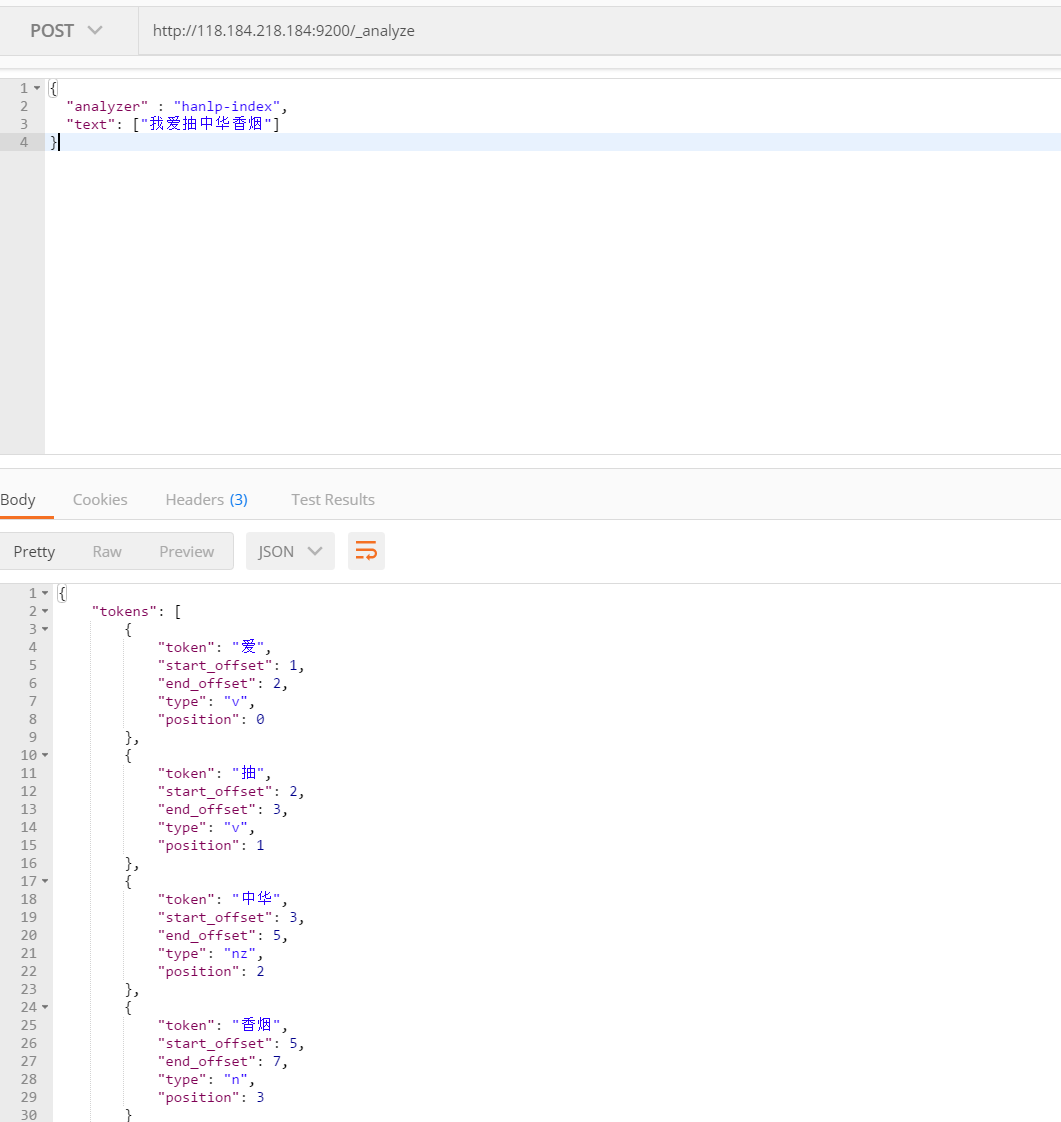
拆分成了”爱”,”抽”,”中华”,”香烟”
假如我们数据库有这几条数据:

“我不是你的中华小子” 拆分后是
{
"tokens": [
{
"token": "中华",
"start_offset": 5,
"end_offset": 7,
"type": "nz",
"position": 0
},
{
"token": "小伙子",
"start_offset": 7,
"end_offset": 10,
"type": "n",
"position": 1
},
{
"token": "小伙",
"start_offset": 7,
"end_offset": 9,
"type": "n",
"position": 2
}
]
}“中华人民共和国,地大物博” 拆分后是
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "ns",
"position": 0
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "nz",
"position": 1
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "n",
"position": 2
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "n",
"position": 3
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "n",
"position": 4
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "n",
"position": 5
},
{
"token": "地大物博",
"start_offset": 8,
"end_offset": 12,
"type": "nz",
"position": 6
}
]
}“我爱你华” 拆分后是
{
"tokens": [
{
"token": "爱",
"start_offset": 1,
"end_offset": 2,
"type": "v",
"position": 0
},
{
"token": "华",
"start_offset": 3,
"end_offset": 4,
"type": "b",
"position": 1
}
]
}如果我用 “我爱抽中华香烟” 去匹配 无疑 3条记录都会显示的
如果我用 “我抽中华香烟” 去匹配 只会有2条记录 因为只有中华才能匹配到数据库的数据,另外一条记录需要用爱这个单词是去匹配
“我抽中华香烟” 的分词如下:
{
"tokens": [
{
"token": "抽",
"start_offset": 1,
"end_offset": 2,
"type": "v",
"position": 0
},
{
"token": "中华",
"start_offset": 2,
"end_offset": 4,
"type": "nz",
"position": 1
},
{
"token": "香烟",
"start_offset": 4,
"end_offset": 6,
"type": "n",
"position": 2
}
]
}插件下载
github:https://github.com/shikeio/elasticsearch-analysis-hanlp
wget https://github.com/shikeio/elasticsearch-analysis-hanlp/releases/download/6.4.2/analysis-hanlp-6.4.2.zip将插件移到elasticsearch6.4.2的plugins目录下
安装目录:/home/elastic/elasticsearch-6.4.2/plugins
mv analysis-hanlp-6.4.2.zip /home/elastic/elasticsearch-6.4.2/plugins
unzip analysis-hanlp-6.4.2.zip
rm -rf analysis-hanlp-6.4.2.zip
mkdir analysis-hanlp
mv * analysis-hanlp修改插件安全策略
vi /home/elastic/elasticsearch-6.4.2/config/jvm.options
-Djava.security.policy=file:///home/elastic/elasticsearch-6.4.2/plugins/analysis-hanlp/plugin-security.policy导入HanLP数据
下载HanLP数据。参见HanLP Releases 下载数据包:新数据包data-for-1.6.8.zip
cd /home/elastic/elasticsearch-6.4.2/plugins/analysis-hanlp
wget http://hanlp.linrunsoft.com/release/data-for-1.6.8.zip
unzip data-for-1.6.8.zip修改config中的数据根,将$ {data.root}更改为您自己的HanLP根数据目录 (这一步可以不配置)
配置环境变量:
su root
vi /etc/profile
export HANLP_ROOT=/home/elastic/elasticsearch-6.4.2/plugins/analysis-hanlp
source /etc/profile重启elasticsearch
kill -9 pid
/home/elastic/elasticsearch-6.4.2/bin/elasticsearch -dPOSTMAN简单测试
查看分词:
POST http://118.184.218.184:9200/_analyze
{
"analyzer" : "hanlp-index",
"text": ["我抽中华香烟"]
}添加索引
PUT
http://118.184.218.184:9200/test/添加Mapping
PUT http://118.184.218.184:9200/test/_mapping/test
{
"propert "content": {
"type": "text",
"analyzer": "hanl "h "hanlp-index",
"search_analyzer": "hanlp-index",
"index_options": "offsets"
}
}
}添加数据
POST http://118.184.218.184:9200/test/test/1
{
"content": ["中华人民共和国","地大物博"]
}查询数据
POST http://118.184.218.184:9200/test/test/_search
{
"query": {
"match": {
"content": "中华"
}
},
"highlight": {
"pre_tags": [
"<tag1>"
],
"post_tags": [
"</tag1>"
],
"fields": {
"content": {}
}
}
}返回结果
{
"took": 384,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "test",
"_type": "test",
"_id": "1",
"_score": 0.2876821,
"_source": {
"content": [
"中华人民共和国",
"地大物博"
]
},
"highlight": {
"content": [
"<tag1>中华</tag1>人民共和国"
]
}
}
]
}
}项目中使用的话:需要改成 @Field(type = FieldType.Text,fielddata = true, searchAnalyzer = “hanlp-index”, analyzer = “hanlp-index”)



